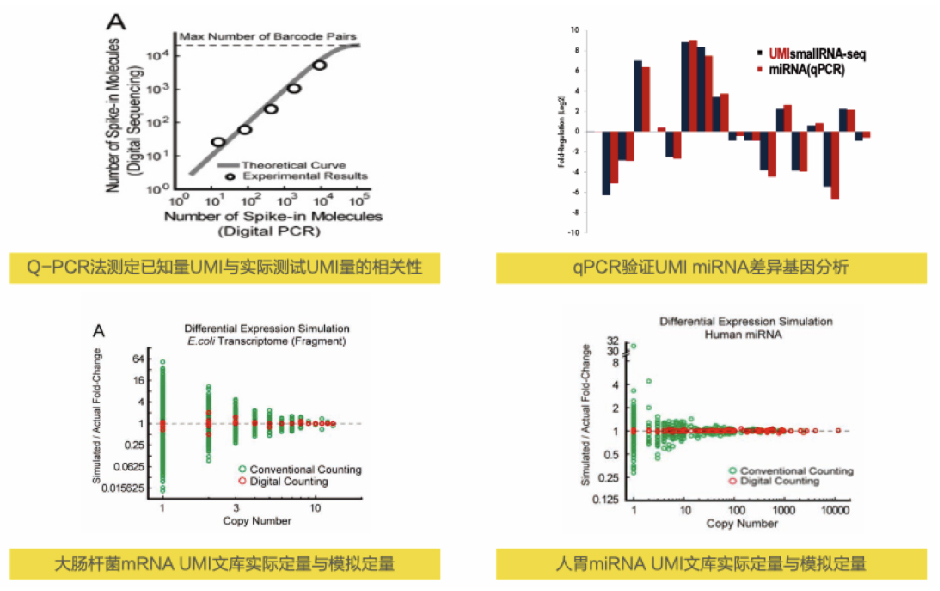
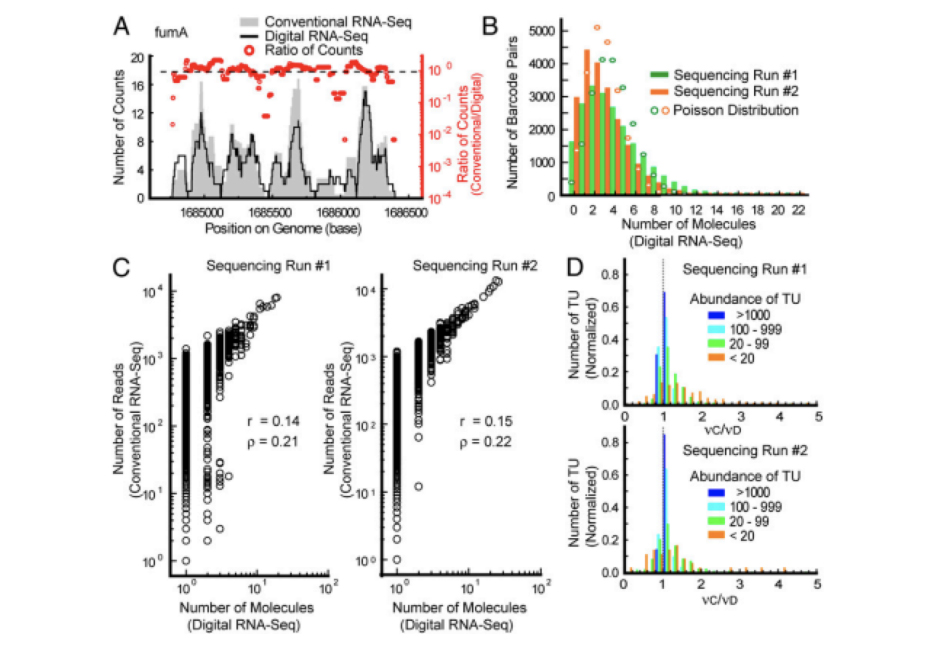
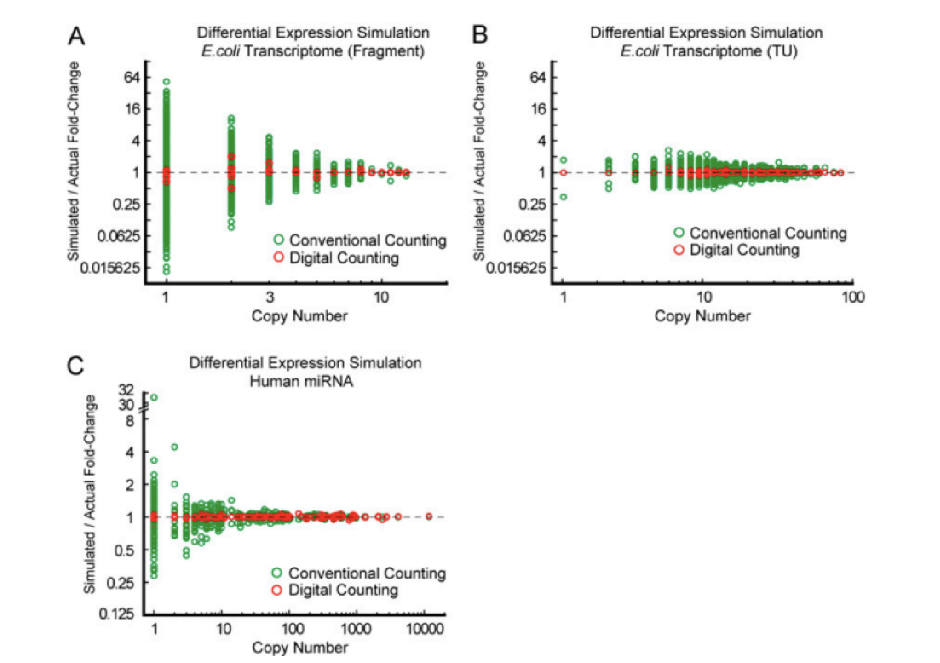
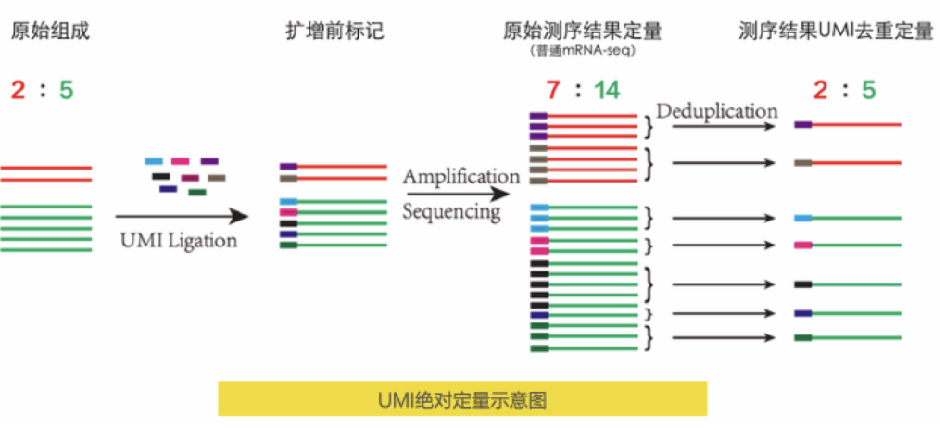
传统miRNA-seq定量分析过程中,由于建库过程中PCR对片段长度和GC碱基含量的偏好会导致部分文库片段丰度失真,进而对定量结果产生影响。UMI(Unique Molecular Identifier)分子标记则通过随机性利用不同的分子标签,标记和区分不同的分子。绝对定量转录组测序(UMI-seq)通过在文库扩增前为每一条逆转录的cDNA添加唯一的分子标签UMI,使同一个片段扩增出来的产物均带有相同的标签,天然重复段则带有不同的标签。利用UMI过滤数据,可一比一准确还原样本初始状态。
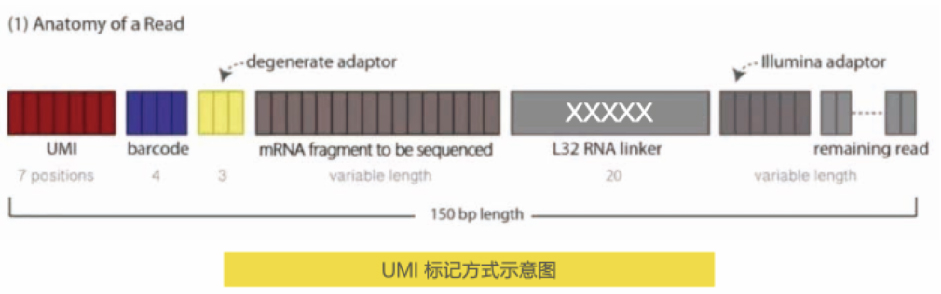
被唯一的随机分子标签标记的cDNA分子,在PCR、测序及后续分析过程中都携带着这个独特的UMI标签。通过计数UMI的个数,可实现原始RNA分子的“绝对定量”。
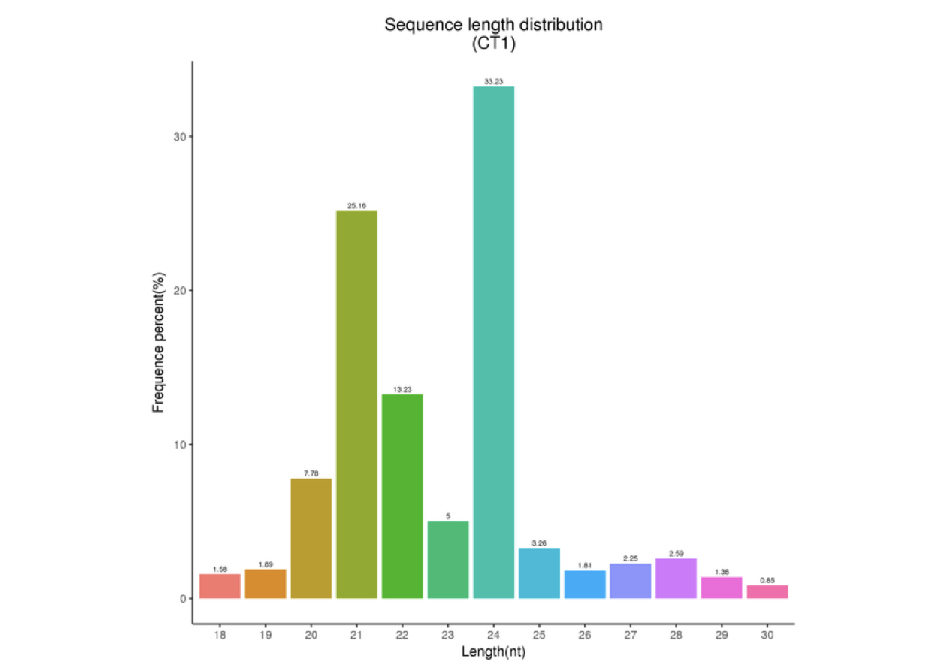
sRNA长度筛选
对各样品的clean reads,筛选一定长度范围内的sRNA来进行后续分析。一般来说,动物sRNA的长度区间为18~35nt,植物sRNA的长度区间为18~30nt,sRNA长度分布的峰图可以帮助我们判断sRNA的种类,如miRNA集中在21~22nt,siRNA集中在24nt等。
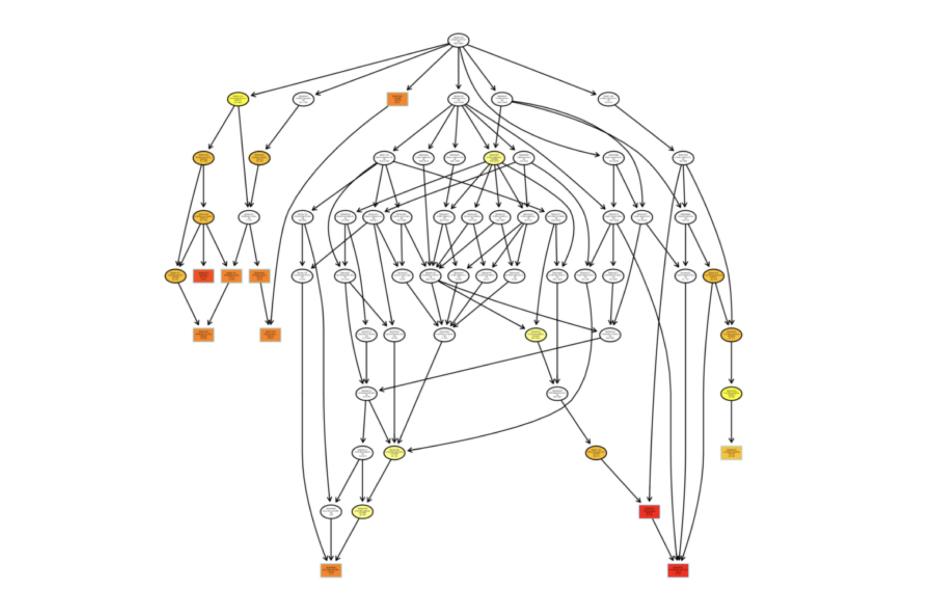
有向无环图(Directed Acyclic Graph,DAG)为候选靶基因GO富集分析结果的图形化展示方式,分支代表包含关系,从上至下所定义的功能范围越来越小,一般选取GO富集分析的结果前10位作为有向无环图的主节点,并通过包含关系,将相关联的GO Term一起展示,颜色的深浅代表富集程度。我们的项目中分别绘制生物过程(biological process)、分子功能(molecular function)和细胞组分(cellular component)的候选靶基因DAG图。
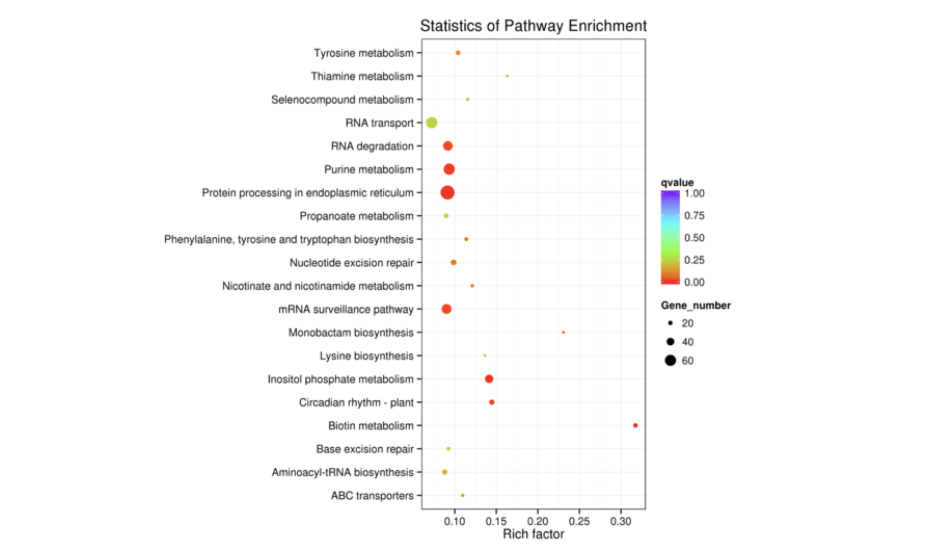
候选靶基因KEGG富集散点图是KEGG富集分析结果的图形化展示方式。在此图中,KEGG富集程度通过Rich factor、Qvalue和富集到此通路上的基因个数来衡量。我们挑选了富集前20位的pathway条目在该图中进行展示,若富集的pathway条目不足20条,则全部展示。

点击进行购买咨询
购买咨询© 2026 GENECHEM All RIGHTS RESERVED .
© 2026 GENECHEM All RIGHTS RESERVED .